エンジニアであり YouTuber の Jeff Gearing は、Mac を低遅延で接続できる macOS 26.2 の新機能を紹介します。RDMA over Thunderboltをテストするには、M3 Ultraを搭載したMac Studioから構成されるAIクラスターを検証しました。
Mac Studio 上の 1.5 TB の VRAM – RDMA over Thunderbolt 5 |ジェフ・ギアリング
https://www.jeffgeerling.com/blog/2025/15-tb-vram-on-mac-studio-rdma-over-thunderbolt-5
Apple はここまで苦労する必要はなかった… – YouTube

Apple が提供する M3 Ultra を搭載した Mac Studio。そのうち 2 つは 32 CPU コア、512 GB のユニファイド メモリ、8 TB ストレージを備えた最上位構成で、残りの 2 つは 256 GB のユニファイド メモリと 4 TB のストレージを備えています。これら4台を含むクラスタ全体の統合メモリは1.5TBに達し、4台の合計コストは約4万ドル(約620万円)弱となる。

インターフェイスに関しては、Mac Studio には 10 ギガビット イーサネット ポートに加えて 5 つの Thunderbolt 5 ポートがあり、Apple によれば、これらのポートはすべて RDMA over Thunderbolt に対応するとのことです。

Mac Studioを収納するラックとして、ギアリング氏デスクピの TL1 と呼ばれる新しい 4 ポスト ミニ ラックを利用します。このミニラックのコンセプトは、机の上や部屋の隅に収まるコンパクトなフォームファクターを提供しながら、ラックマウント型機器の利点を提供することを目的としています。

ここで最も問題となるのは電源ボタンの配置です。 Mac Studio の電源ボタンは背面の右側の丸い角にあるため、ラックに置いた場合は非常に使いにくくなっています。以前ギアリングさんが使用していた卓上ラックマウントは、正面からボタンを押すために複雑なアーム機構が必要でしたが、このミニラックは側面が開いているので、横から手を入れてボタンを押すことができます。

一方、ポートはシャーシの前面に配置されているため、管理用のキーボードやモニターを接続するのに便利です。また、小型PCの多くは本体を小さく見せるために巨大なACアダプタを外付けしていますが、Mac Studioは電源を内蔵しているため、ラック内の配線の取り回しが煩雑になりにくいというメリットもあります。

Gearing は、Mac Studio クラスターのパフォーマンスを調査する際に、比較のために 2 つの AI デスクトップ システムを選択しました。 1つはNVIDIAですDGXスパーク同じチップを搭載しながら冷却性能が向上GB10 を搭載した Dell Pro Maxは。このシステムの価格は、今回のテスト構成で約4000ドル(約63万円)となる。

もう1つはAMD製ですAIマックス+ 395これはチップを搭載したFramework Desktopのメインボードを利用したシステムで、価格は約2,200ドル(約32万4,000円)。

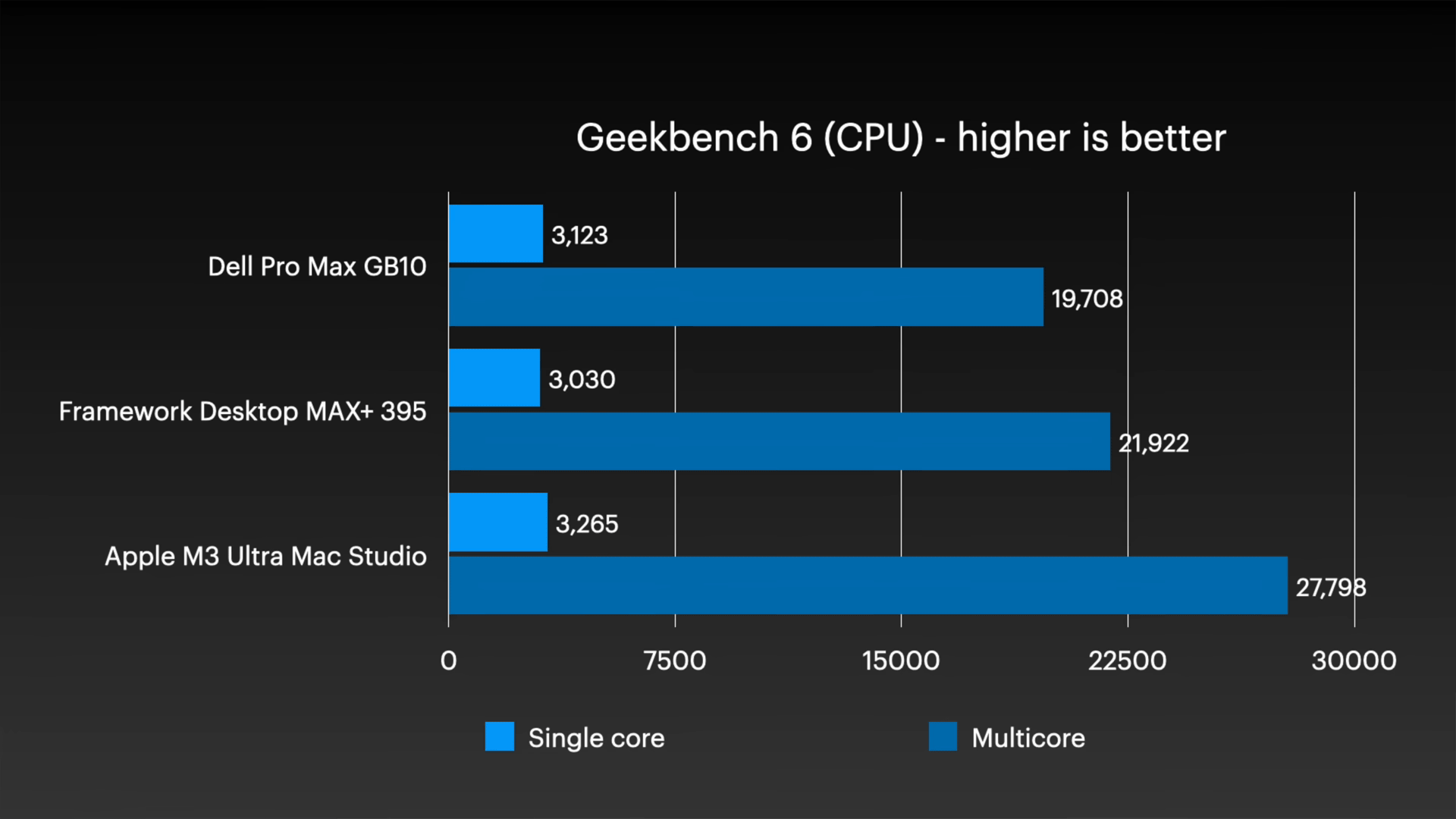
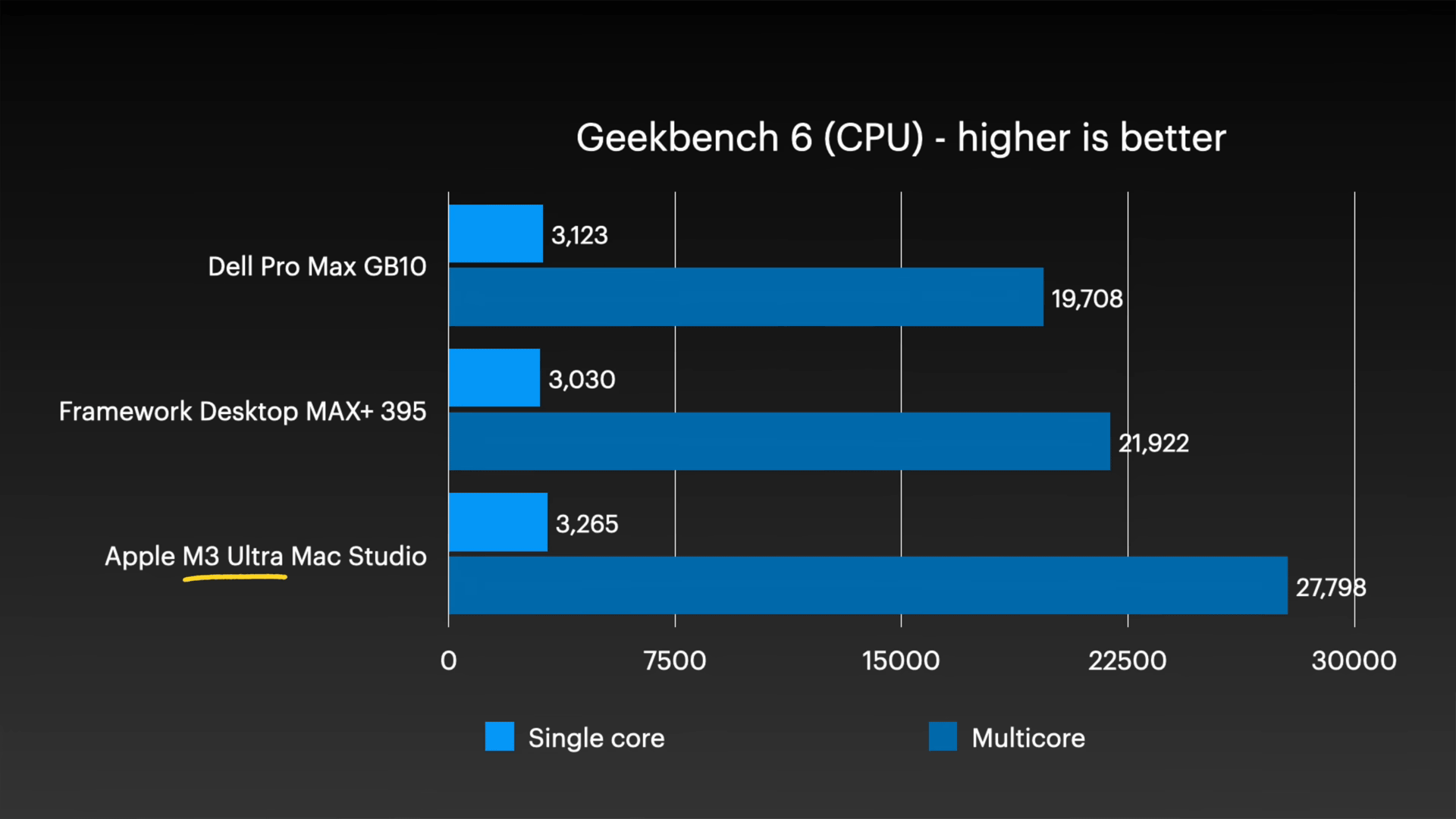
まず、Geekbench 6におけるシングルコア(水色)とマルチコア(紺色)の比較は以下の通り。 2 世代前の CPU コアを搭載した M3 Ultra Mac Studio は、GB10 と Framework Desktop を搭載した Dell Pro Max を上回りました。
倍精度 (FP64) テストでは、M3 Ultra Mac Studio は 1TFLOPS 以上を達成しました。これは、GB10 を搭載した Dell Pro Max のほぼ 2 倍、Framework Desktop の 4 倍以上の速度です。
CPU効率についてGearing氏は「これはすべてのApple製チップに言えることだが、驚くべきことだ」と述べた。
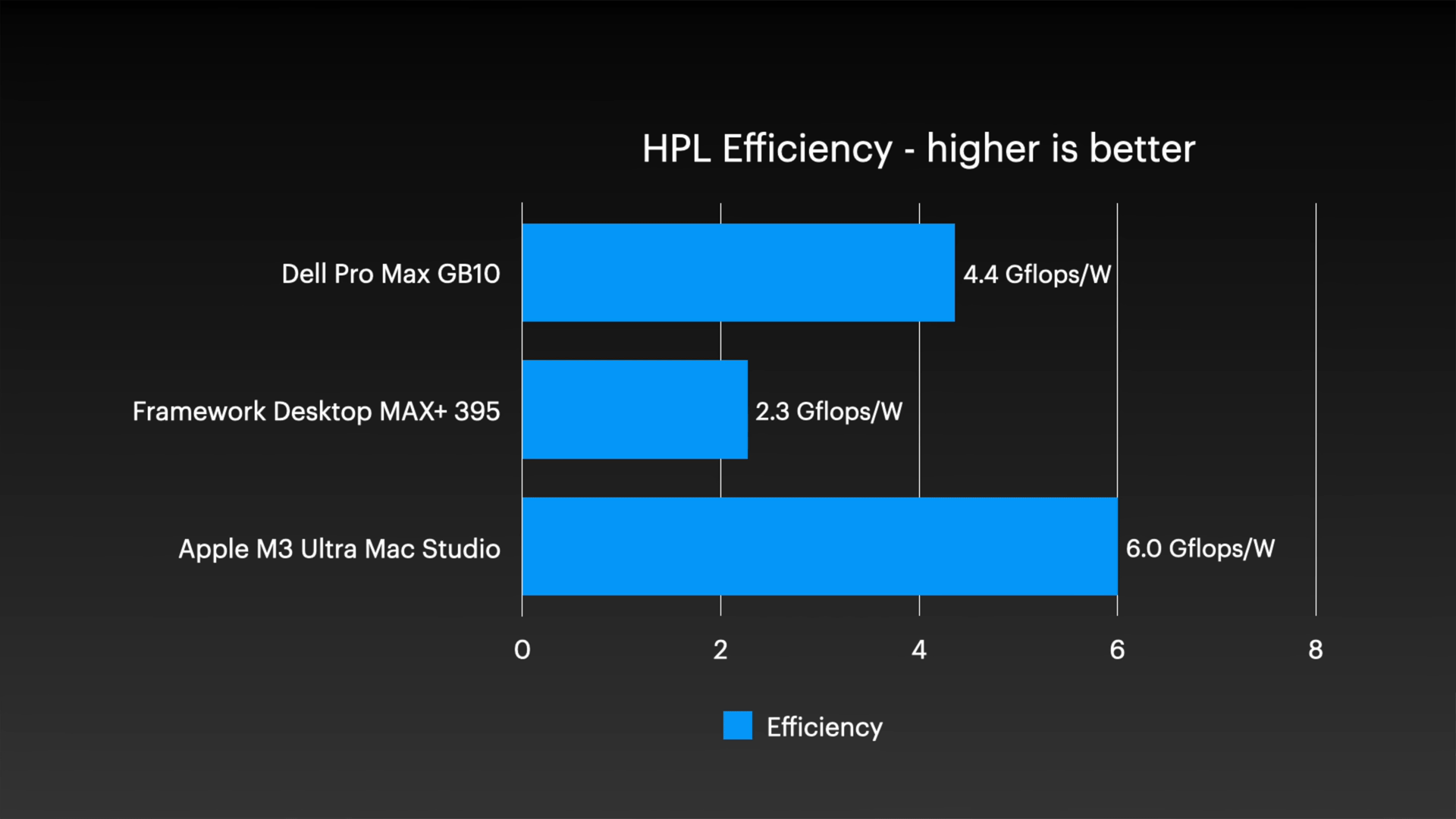
また、M3 Ultra Mac Studio のアイドル時の消費電力は 10W 未満です。
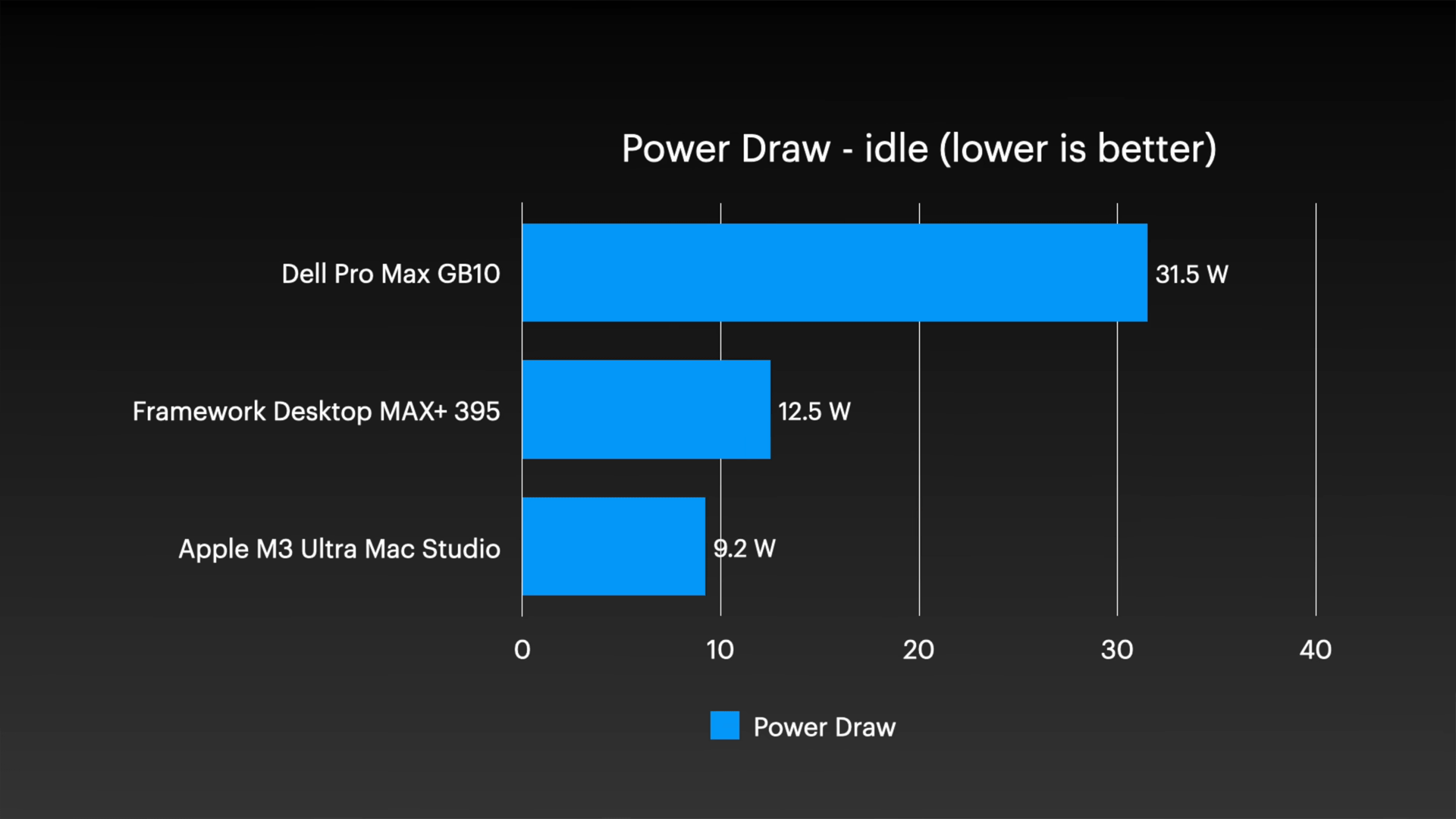
AI 推論テストに関しては、単体でも Mac Studio の優位性は明らかです。 Llama 3.2 3B を使用したテストでは、Mac Studio は 1 秒あたり 154.6 トークンを記録しましたが、Dell は 1 秒あたり 97.9 トークンを記録しましたが、Framework は 1 秒あたり 88.1 トークンのみを記録しました。
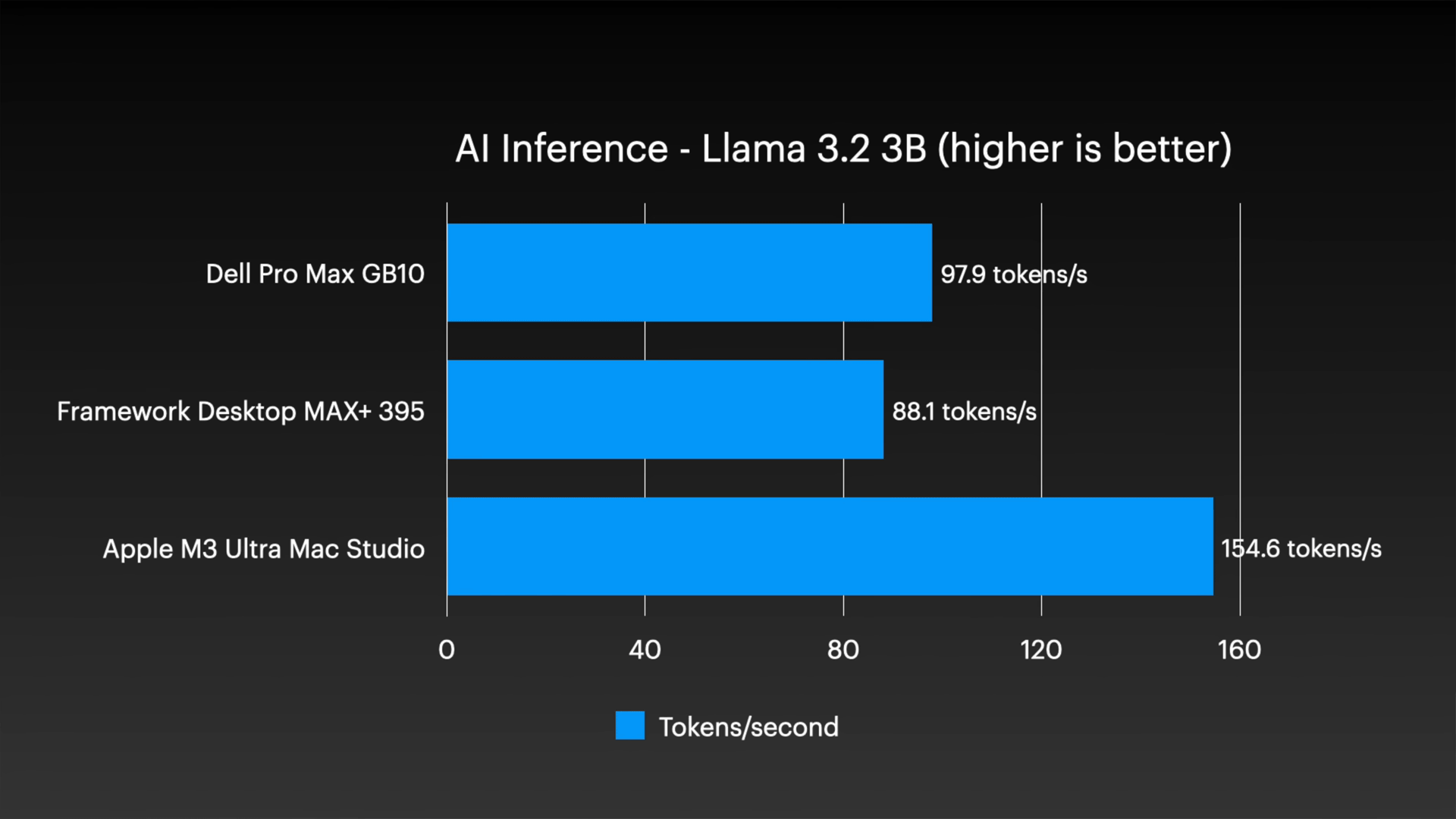
さらに大きな Llama 3.1 70B では、Mac Studio は 1 秒あたり 14.1 トークンを維持しましたが、他の 2 つのシステムは 1 秒あたり約 5 トークン以下に大幅に減少しました。
特に DeepSeek R1 のような非常に大規模なモデルになると、他の 2 つのシステムを使用して単一ノードで実行することは不可能であり、Mac Studio の巨大なユニファイド メモリの優位性は明らかです。
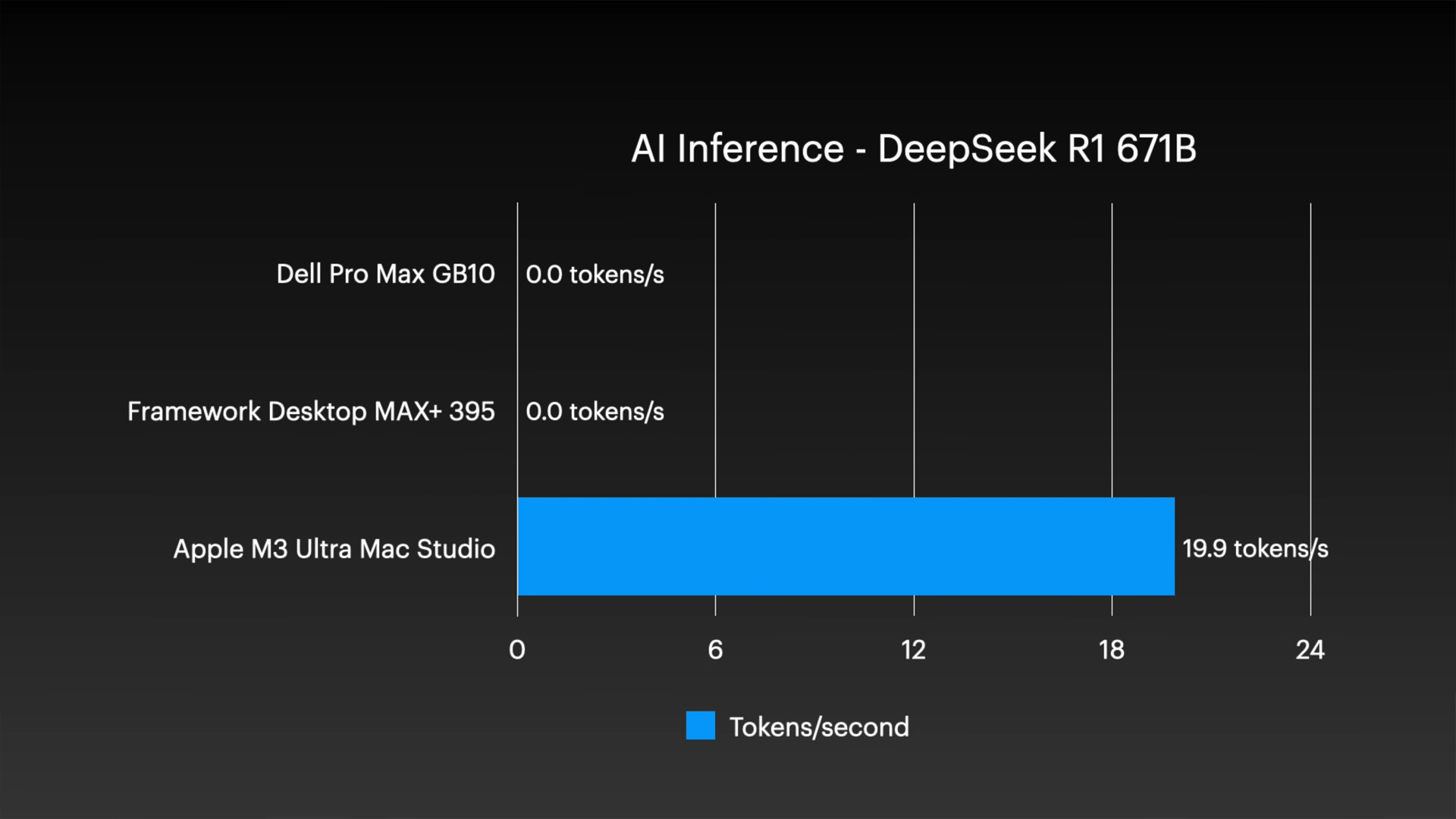
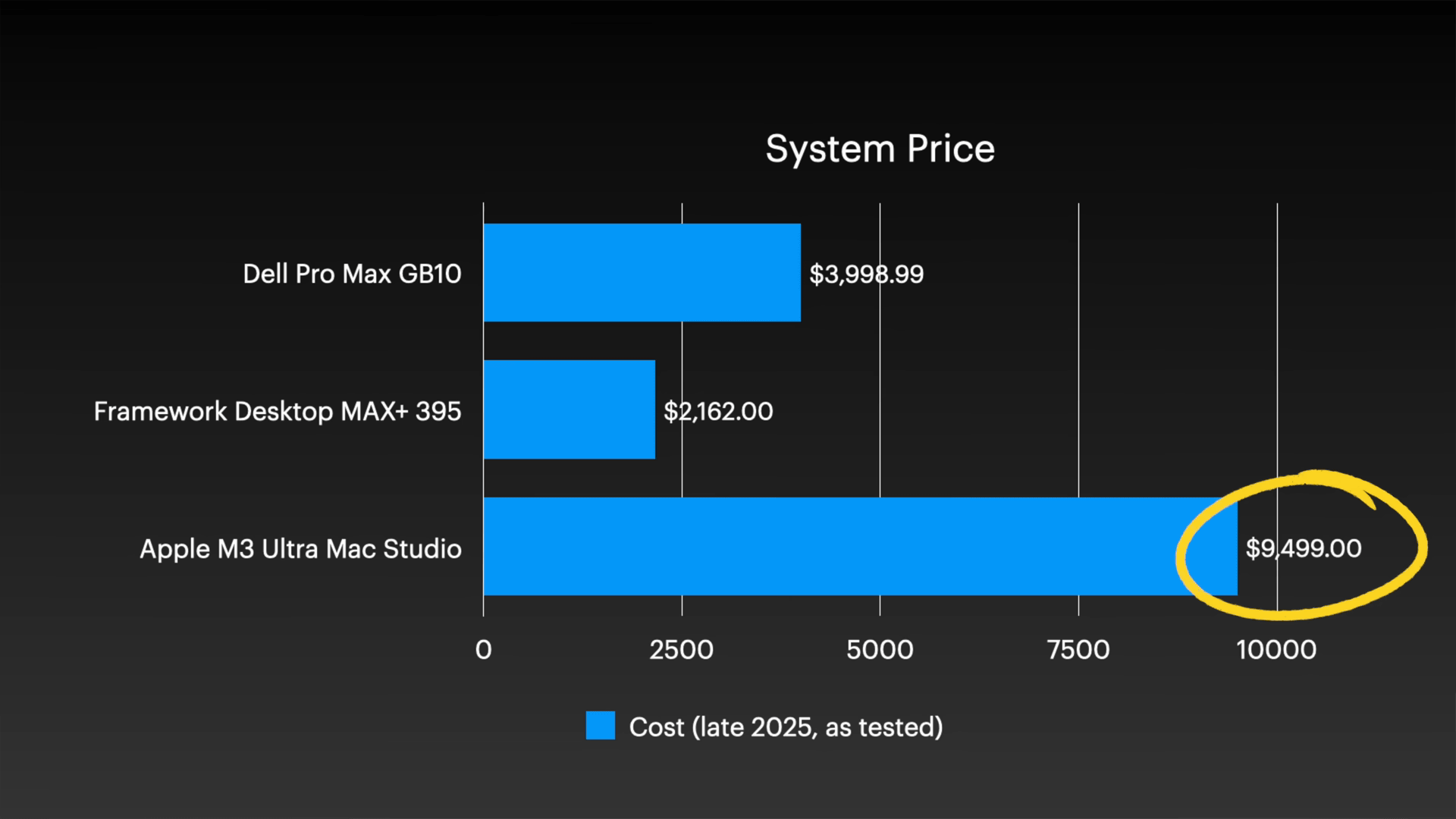
ただし、Mac Studio クラスタのコストは 1 台あたり約 9,500 ドル (約 150 万円) と、他の 2 つのシステムに比べてかなり高価であることに注意が必要です。
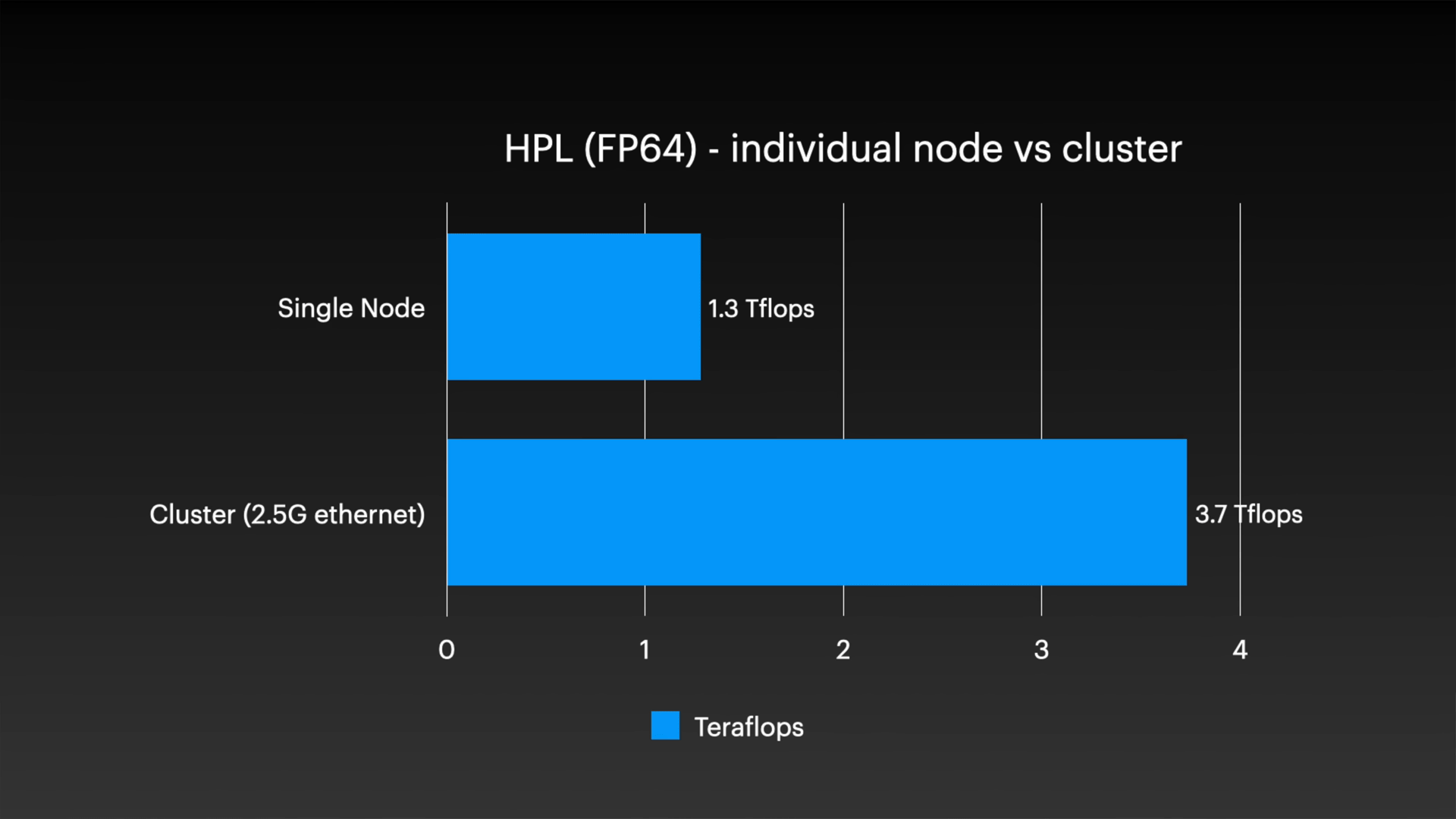
クラスタリングのスケーリング性能についても詳細な検証を行いました。 HPL を使用したテストでは、単一ノードの 1.3 TFLOPS と比較して、4 ノードのクラスター構成では 3.7 TFLOPS を記録し、約 2.8 倍の高速化が確認されました。クラスター内の 2 台のマシンのメモリ容量が他のマシンの半分しかないことを考慮すると、これは期待値に近いスケーリング パフォーマンスです。
一方、Thunderbolt 5でTCP通信を利用した場合、高負荷時にシステムがクラッシュしたり再起動したりする不安定な動作が観察されました。
分散 AI 推論のための RDMA over Thunderbolt と従来の TCP 通信の比較研究では、ネットワーク遅延とスケーラビリティの点で決定的な違いが確認されました。 RDMA over Thunderboltを利用したクラスターを構築するために、ギアリング氏は複数のデバイスをネットワークに接続し、AI処理用のクラスターを作成できるシステム「exo」を利用している。
「Exo」はスマホやPCなど自宅にあるコンピューティングリソースを集めて独自のAIクラスターを構築できる – GIGAZINE

従来の TCP ベースの接続では、メモリ アクセスの遅延は約 300 マイクロ秒でしたが、RDMA over Thunderbolt を有効にすることで、メモリ アクセスの遅延は 50 マイクロ秒未満に劇的に短縮されました。この低レイテンシにより、複数の Mac Studio に分散されたメモリが 1 つの巨大な共有メモリ プールであるかのように動作できます。
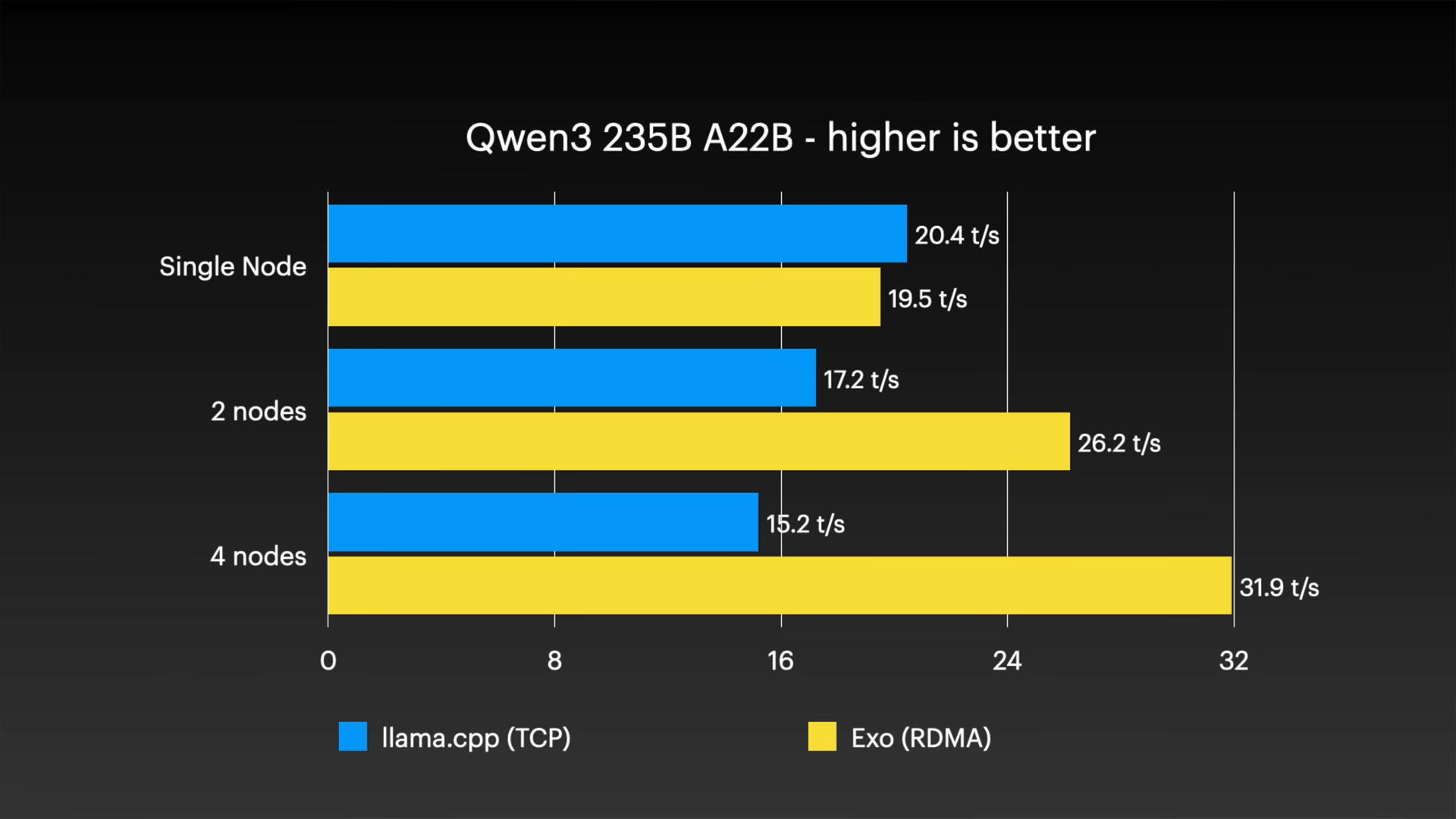
推論速度の検証結果を見ると、通信プロトコルの違いがパフォーマンスのスケーリングに影響を与えていることがわかります。従来の TCP 接続を使用する llama.cpp の RPC 方式では、計算ノードが追加されるほどネットワーク オーバーヘッドが蓄積し、推論速度が低下する傾向があります。
たとえば、Qwen3 235B A22B モデルを使用したテストでは、llama.cpp の速度が、1 ノードで 1 秒あたり 20.4 トークンから 4 ノードで 15.2 トークンに低下しました。対照的に、RDMA over Thunderbolt が有効になっている EXO 環境では、ノードを 1 つ追加したときの速度が 1 秒あたり 19.5 トークンから増加し、4 ノード構成では 1 秒あたり 31.9 トークンの高スループットが記録されました。
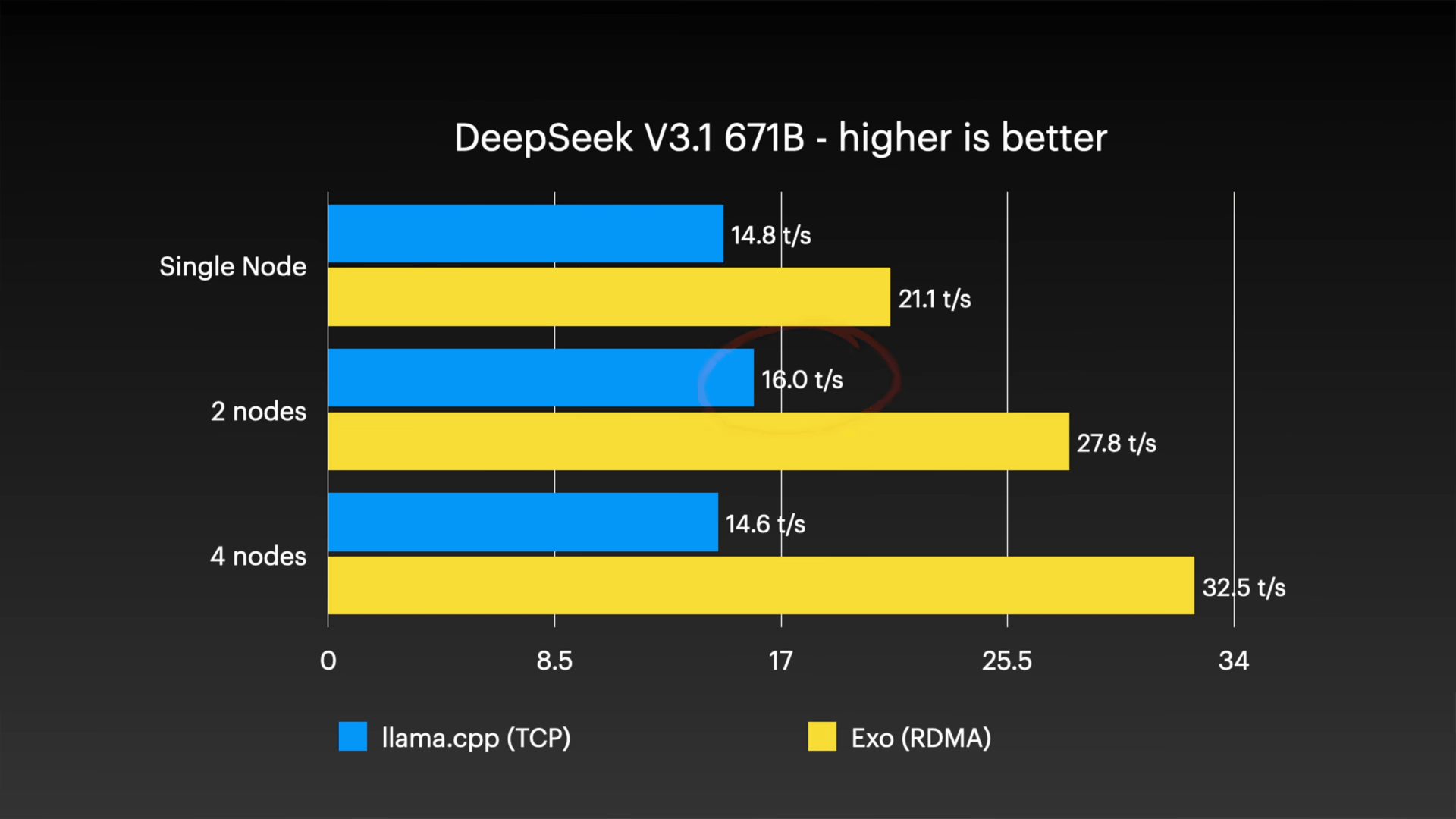
さらに、6,710億個のパラメータを持つ巨大なモデルであるDeepSeek V3.1でも同様の傾向が確認されており、exo環境では4ノード構成で毎秒32.5トークンに達し、14.6トークン/秒のllama.cpp(TCP)と比べて2倍以上の性能差となっています。
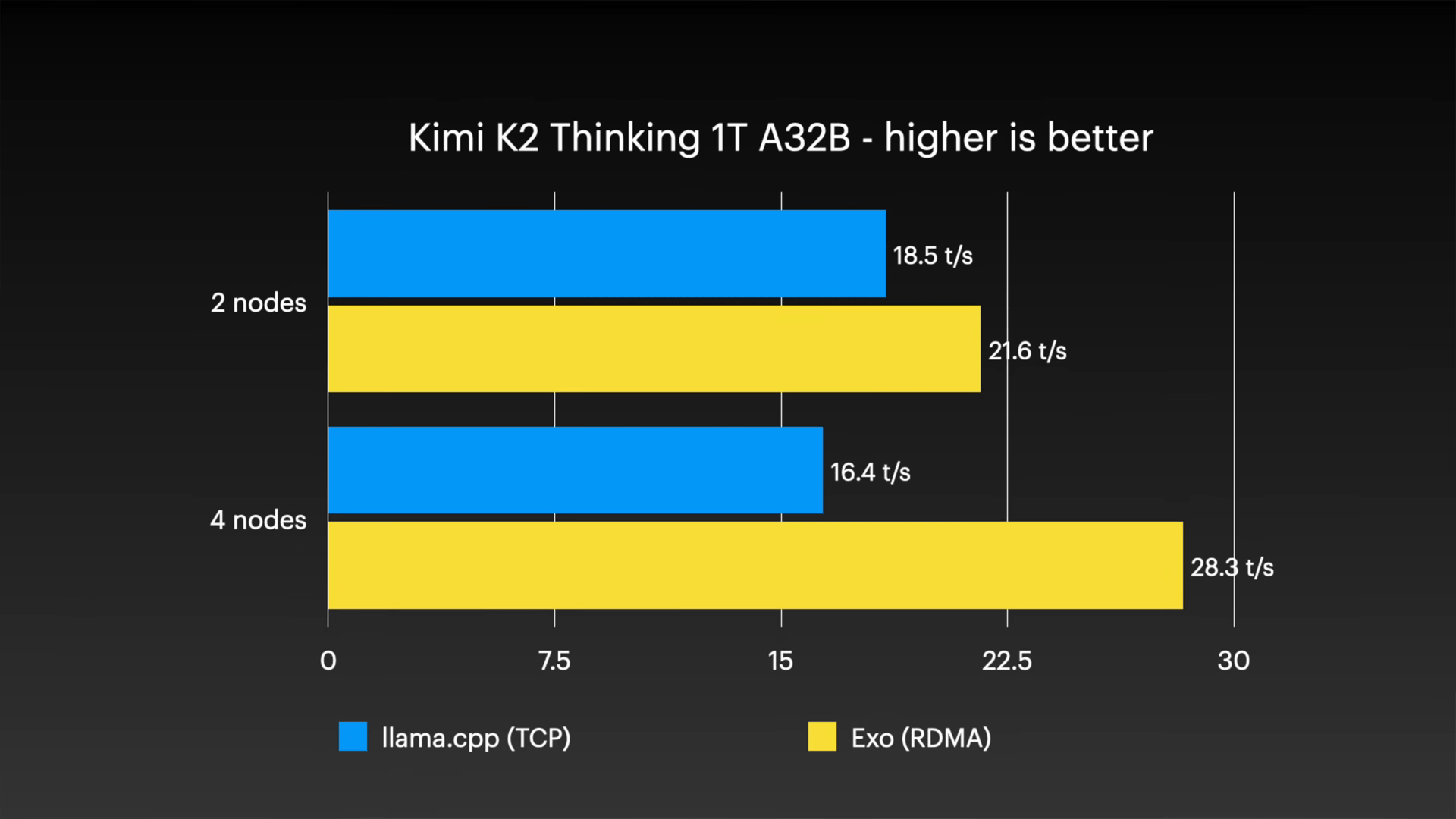
また、今回の検証で最大となるパラメータ数1兆個(アクティブパラメータ320億個)のKimi K2 Thinkingモデルは、exo環境の4ノード構成で毎秒28.3トークンを記録し、実用レベルの会話速度を実現しました。
ただし、今回の検証で使用したEXOはプレリリース版であり、テストの過程で多くのバグは修正されているものの、安定性の点でまだ課題が残っている。特に、Thunderbolt による RDMA は新しい技術であるため、正常に動作しているときは非常に優れたパフォーマンスを発揮しますが、ひとたび問題が発生するとシステムが制御不能になる可能性がある不安定性もあります。
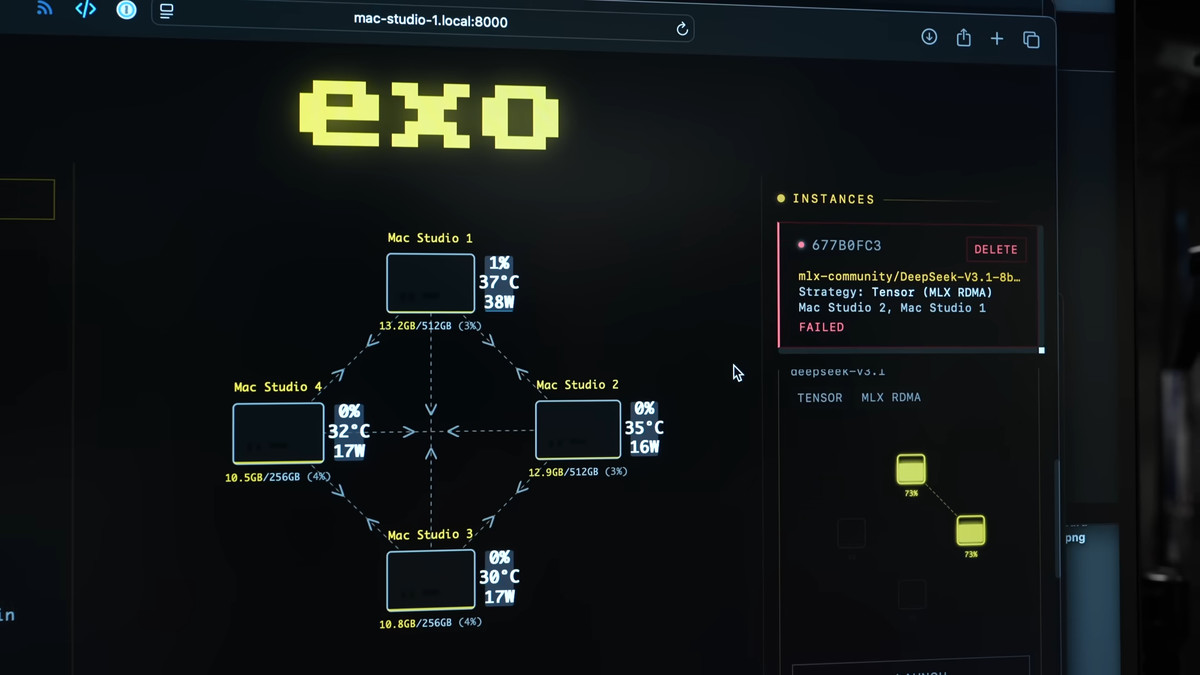
この不安定性に備えるために、Gearing は構成管理ツールを使用します。アンシブル事前に設定されていました。 Gearing氏は、クラスタ全体がダウンした場合でも、各ノードを1台ずつ手動で操作することなく、スクリプトを使用してすべてのノードを素早くシャットダウンして再起動することができ、検証作業を継続するのに大いに役立ったという。
ギアリング氏は、EXOの開発チームはしばらく活動を休止しており、Appleとの開発プロセスも不透明であり、ハードウェア、ソフトウェアの両面で開発段階にあると指摘しました。
この記事のタイトルとURLをコピーします