

ChatGPT には、会話の内容や個人情報を記憶する高精度の記憶システムが搭載されています。 AIエンジニアマンタン・グプタChatGPTがユーザー情報をどのように記憶しているのかを「ChatGPTの記憶システムをリバースエンジニアリングしてわかったこと」として報告した。
ChatGPT のメモリ システムをリバース エンジニアリングしたところ、次のことがわかりました。 – マンタン
https://manthanguptaa.in/posts/chatgpt_memory/
Gupta 氏によると、ChatGPT のメモリ システムは予想よりもはるかに単純で、ベクトル データベースには会話履歴も保存されます。検索拡張生成(RAG)それも使われていないという。代わりに、4 つの異なる層からなる単純な記憶システムを利用しているようです。
以下は、ChatGPT が各入力に対して受け取るコンテキスト構造です。このうち、「[0]「システム説明書」と「[1]「開発者向け指示」については説明しません。なぜなら、「開発者向け指示」は開発者によって指定された高レベルの動作と安全ルールを定義しているからです。また、”[6]「あなたの最新のメッセージ」はユーザーが入力したばかりのメッセージでもあるため、「あなたの最新のメッセージ」に焦点が当てられます。[2]「セッションメタガタ」から「[5]「Current Session Messages」までのメッセージは4つあります。

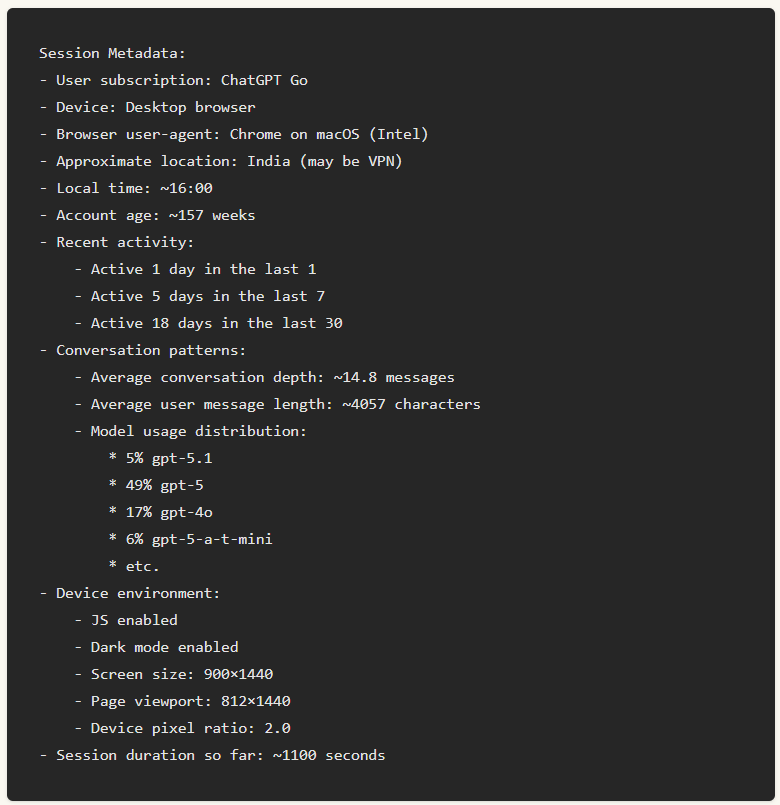
[2]セッションメタガタ
これらのメタデータは、ChatGPT でセッションを開始するたびに 1 回だけ挿入され、永続的または長期メモリには保存されません。このメタデータには、「ブラウザの種類(デスクトップ/モバイル)」、「ブラウザの種類」、「ユーザーの一般的なタイムゾーンと場所」、「サブスクリプションレベル」、「使用パターンとアクティビティ頻度」、「最近のモデルの使用傾向」、「画面サイズ、ダークモードのステータス、JavaScriptの有効化など」などが含まれる。
たとえば、Gupta氏の調査では、次のようなメタデータが挿入されました。このデータは、ChatGPT が環境に合わせて応答を調整するのに役立ちますが、セッション終了後は保持されません。
[3]ユーザーメモリ
ChatGPT には、ユーザーに関する長期情報を保存および削除するための専用ツールがあり、このツールが数週間または数か月にわたって蓄積した情報は、ユーザーの永続的なプロファイルになります。例えばグプタさんの場合、「名前」「年齢」「キャリア目標」「キャリアと過去の仕事」「現在のプロジェクト」「研究分野」「フィットネス習慣」「個人的な好み」「長期的な興味」など計33件の事実が保存された。
これらは ChatGPT によって推論されませんが、ユーザーによって「この情報を記憶/保存する」ように指示されるか、会話を通じて ChatGPT に伝達されます。これらのユーザー メモリは、将来のプロンプトに個別のブロックとして挿入され、ChatGPT によって生成されたメッセージに影響を与えます。ユーザーメモリの内容を削除したい場合は、ChatGPT に「これをメモリから削除…」と指示できます。
たとえば、Gupta 氏の場合、次のようなユーザー メモリが保存されていました。

[4]最近の会話の概要
Gupta氏は当初、ChatGPTは過去の会話履歴を徹底的に検索し、生成されるメッセージに反映するRAGを利用していると考えていたが、実際には軽量な「最近の会話の概要」を利用していることが判明した。会話の要約はユーザー メッセージのみを対象とし、ChatGPT によって生成されたメッセージは要約されません。グプタ氏のまとめは15の事例にまとめられており、詳細な文脈というよりも「会話の大まかな地図」として機能しているようだ。
RAGを採用すると、システムを動作させるたびに「過去のメッセージをすべて読み込む」「クエリごとに類似検索を行う」「完全なメッセージコンテキストを取得する」といった処理が必要となり、レイテンシやトークン消費量の増大といった問題が発生する。ただし、ChatGPT は会話を事前に要約して引き継ぎ、詳細なコンテキストを犠牲にして速度と効率を向上させます。
[5]現在のセッションのメッセージ
また、ChatGPT は現在のセッション内のすべてのメッセージを完全に引き継ぎ、一貫したセッション応答を保証します。このレイヤーに保存されるメッセージの最大数はトークンに基づいており、制限に達すると最も古いメッセージが削除されますが、削除された内容はユーザーの記憶や会話の概要にも引き継がれます。

Gupta氏はChatGPTにメッセージを送信する際の操作を以下のようにまとめています。
1: セッションの開始時にメタデータが挿入され、デバイス、サブスクリプション、使用パターンに関するコンテキストが提供されます。
2: 保存されたユーザーメモリは常に与えられ、応答はユーザーの好みに合わせて調整されます。
3: 完全な履歴ではなく、軽い概要を参照して、最近の会話を振り返ります。
4: 現在のセッション メッセージはすべて記憶され、会話の一貫性が保たれます。
5: 現在のセッションが長すぎる場合、最も古いセッションは削除されますが、ユーザーの記憶と会話の概要は継続されます。
この階層化されたアプローチを採用することで、ChatGPT は、何万もの過去のメッセージを検索するコストをかけずに、一貫した応答を実現します。
「ChatGPT のメモリ システムは、パーソナライゼーション、パフォーマンス、トークン効率のバランスをとる多層アーキテクチャです。一時的なセッション メタデータ、明示的な長期事実、軽量な会話の概要、および現在のメッセージのスライディング ウィンドウを組み合わせることで、ChatGPT は驚くべき結果を達成します」と Gupta 氏は述べています。 「トレードオフは明らかです。ChatGPT は速度と効率のために詳細な歴史的背景を犠牲にしています。しかし、ほとんどの会話では、それが適切なバランスです。」
なお、この情報はChatGPTとの会話のリバースエンジニアリングによって発見されたものであり、OpenAIの公式ドキュメントに基づいたものではないため、あまり当てにしないでください、とGupta氏は付け加えた。
この記事のタイトルとURLをコピーします














