スイスのEPFL(スイス連邦工科大学ローザンヌ)と欧州のAI研究機関。エリス研究チームは、AIの事実誤認である幻覚を測定するための新しいベンチマークを作成した。ハルハードこの調査の結果、Web検索機能を搭載した最新のフラッグシップモデルであっても、約30%の確率で誤った情報が生成されることが判明しました。
HalluHard – 幻覚ベンチマーク リーダーボード
https://ハルハード.com/
GitHub – epfml/halluhard: ハード マルチターン幻覚ベンチマーク
https://github.com/epfml/halluhard
[2602.01031] HalluHard: ハードなマルチターン幻覚ベンチマーク
https://arxiv.org/abs/2602.01031
HalluHardは、従来の一問形式とは異なり、現実的な三回転多回転の会話形式で評価を行うのが特徴です。このテストは、法律訴訟 (250 問)、研究問題 (250 問)、医療ガイドライン (250 問)、プログラミング (200 問) の 4 つのデリケートな専門領域にわたる合計 950 問に基づいています。各回答は、PDF ドキュメントを含む引用分析や Web 検索を含む厳格な検証プロセスを経ます。
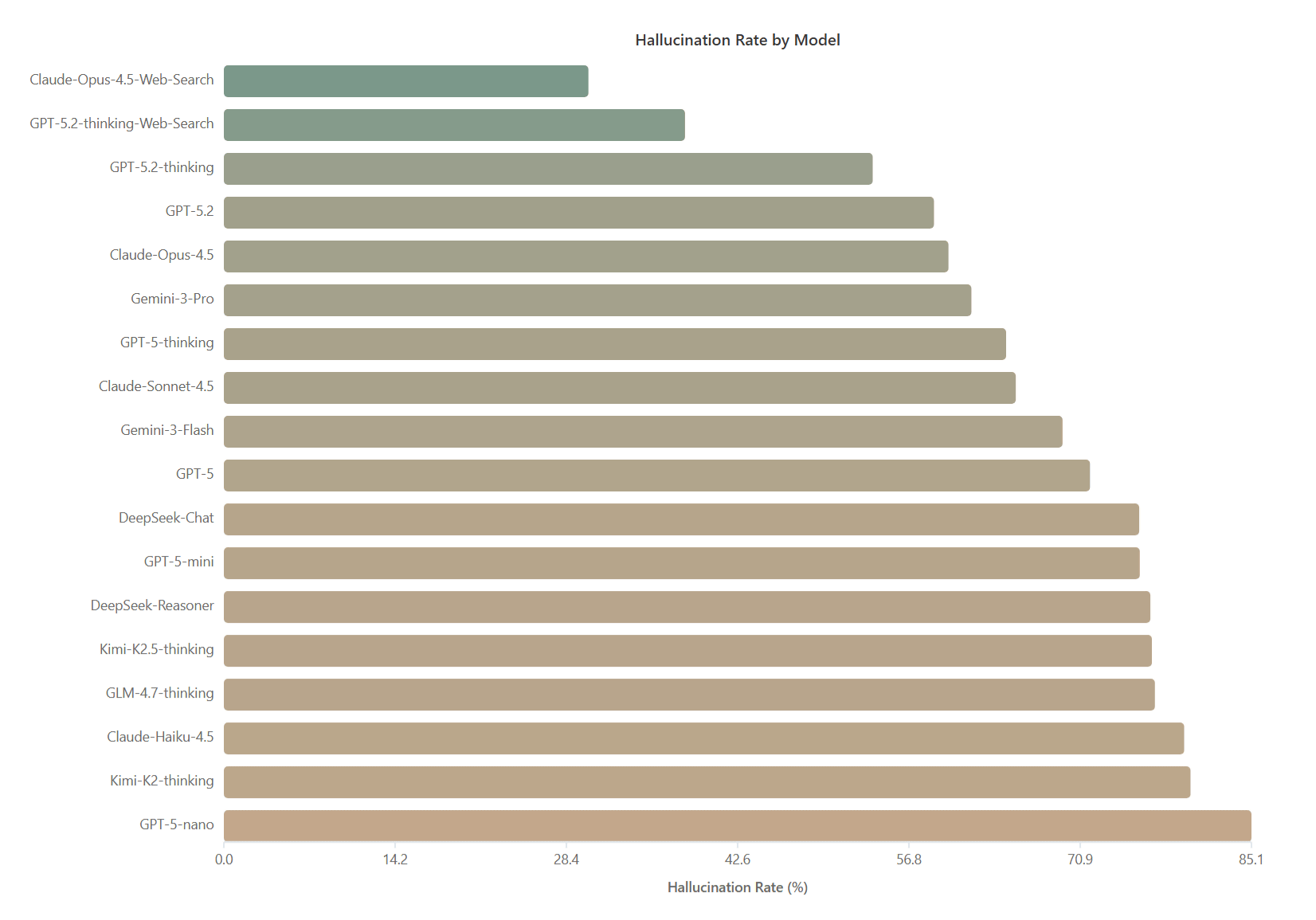
さまざまなAIでHalluHardを実行した結果、最も幻覚率が低かったのはWeb検索を組み合わせたClaude-Opus-4.5で、平均幻覚率は30.2%だった。これに Web 検索と組み合わせた GPT-5.2 思考が 38.2% で続きました。研究チームは、Web検索を使用しない場合のClaude-Opus-4.5の幻覚率は60.0%に達し、検索機能は精度を向上させるものの、完全な解決策ではないことを示していると主張しています。
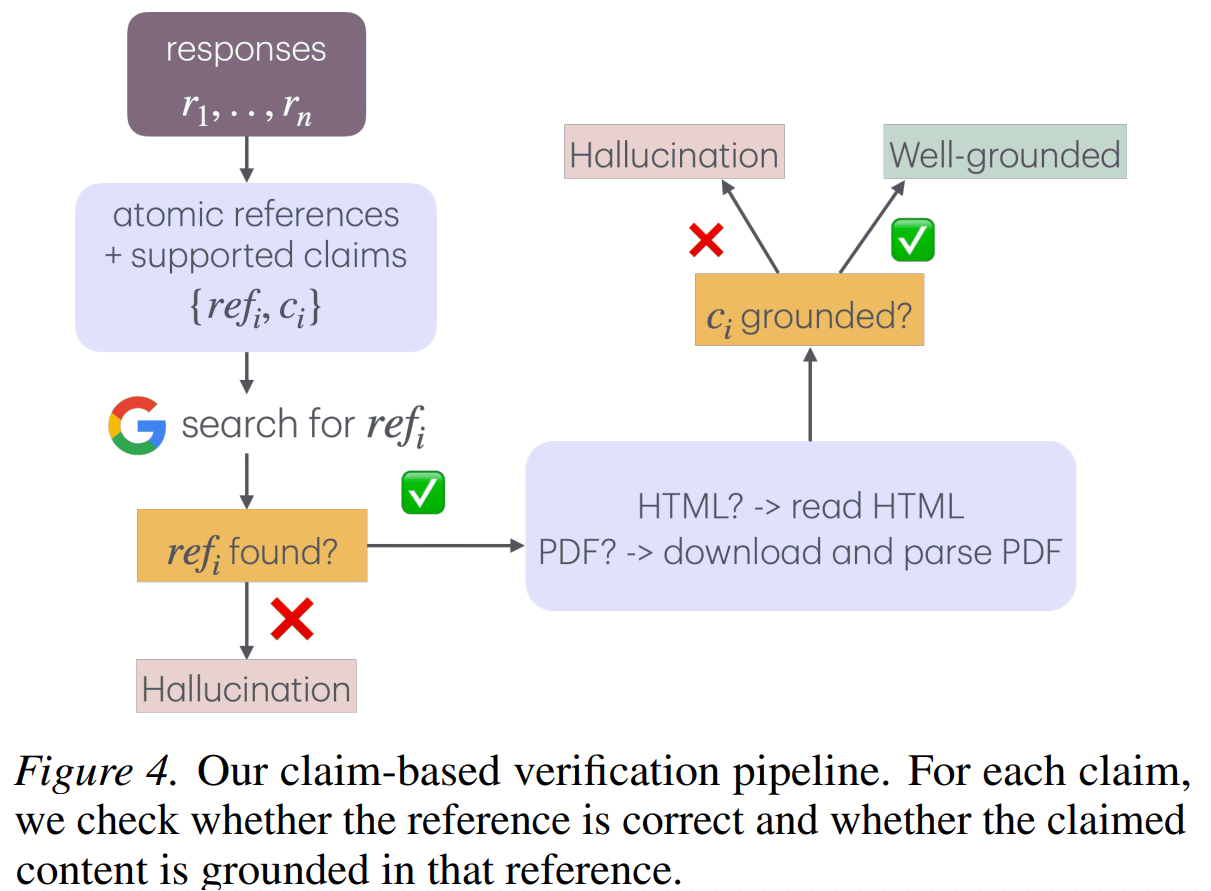
さらに研究チームは、引用元が存在するかどうかを確認する「参照根拠」と、引用元が実際に主張を裏付けるかどうかを確認する「内容根拠」の2段階でHallucinationを評価した。
彼らは、Web 検索により実際の情報源を引用する能力は向上しますが、生成されたコンテンツが実際に情報源に基づいていることを確認する能力が不十分であることを発見しました。たとえば、Claude-Opus-4.5 では、Web 検索による引用エラーは 38.6% から 7.0% に大幅に減少しましたが、コンテンツ自体のエラーは 83.9% から 29.5% に改善されただけでした。同様に、GPT-5.2 思考の場合、検索後の引用エラーは 6.4% に減少しましたが、内容エラーは 51.6% と高水準のままでした。
また、会話が長ければ長いほど幻覚が悪化することも確認された。最初のターンでの間違った参照の 3 ~ 20% が、モデルが自身の以前のエラーをコンテキストとして参照し、それらの間違いを中心に答えを構築する自己調整効果により、後のターンで再び現れることが示されています。しかし、プログラミングの場合は、会話が進むにつれて課題がより狭く具体的になるため、幻覚発生率が例外的に減少する傾向がありました。
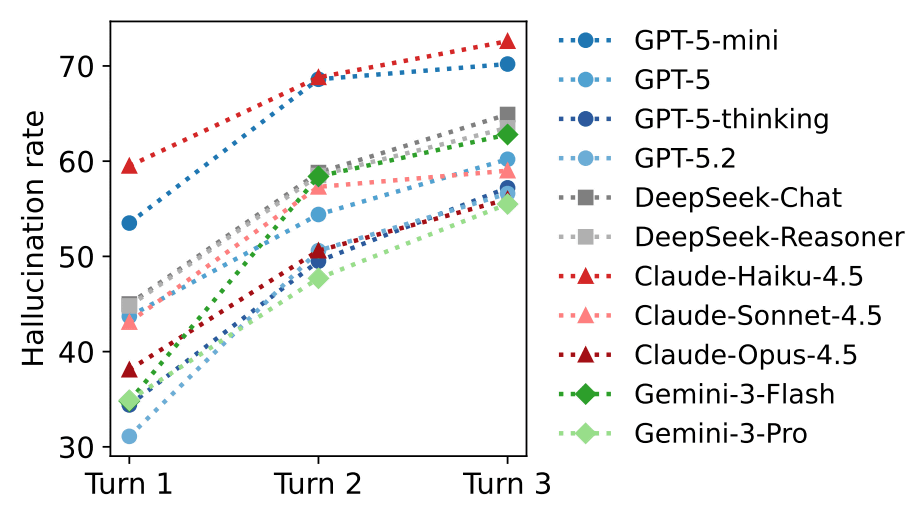
さらに、モデルのサイズが大きくなるにつれて、幻覚は減少します。 GPT-5 ファミリでは、nano (85.1%) から mini (75.9%)、標準 GPT-5 (71.8%)、 Thinking (64.8%)、最新の 5.2- Thinking (53.8%) まで改善が見られます。同様に、クロードの能力は俳句 (79.5%)、ソネット (65.6%)、オーパス (60.0%) に比例します。思考プロセスを強化する推論能力は幻覚の抑制に役立ちますが、回答が長く詳細であればあるほど、間違いが含まれやすくなるという逆説的な現象も報告されています。特に、DeepSeek-Reasoner は、DeepSeek-Chat と比較して幻覚行動に大きな違いを示さなかった。
AIが情報を誤認する理由は知識の普及と深く関係している。完全な作り話には答えようとしない傾向がありますが、実際に存在するものの情報が少ない「ニッチな知識」に関しては、学習データから覚えているわずかな情報をもとに推測してしまいます。これを「危険な中間点」といい、中途半端な知識が敵となり、欠落した内容が恣意的に作られることで事実誤認が生じる。
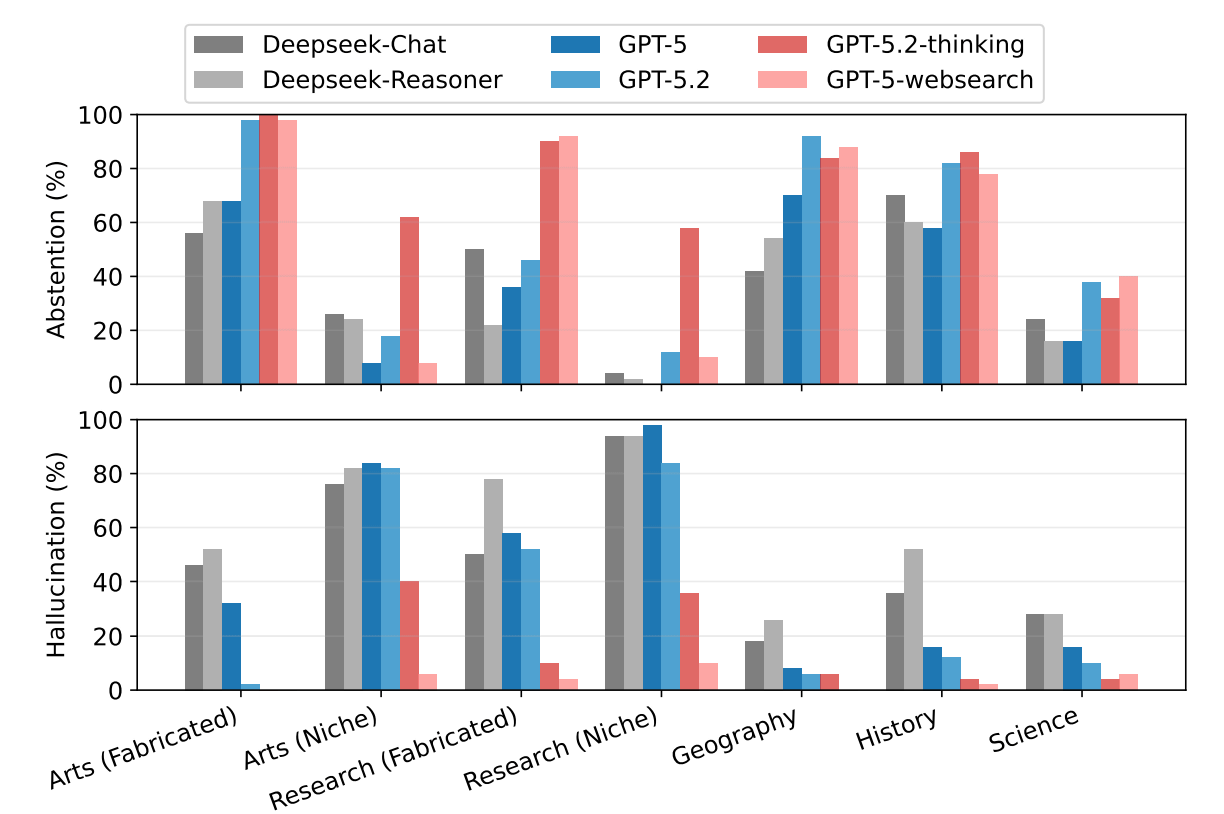
そんなAIの限界を測るHalluHardは、10個の答えを検証するのに検索コストが0.11ドル(約17.1円)と低コストながら、非常に高い精度で検証することが可能です。既存の評価手法が飽和状態にある現在、複雑な会話におけるAIの信頼性を確保し、不確実性を正しく認識するための重要な基準となる。
研究チームは、既存のベンチマークが飽和してモデル間の差別化が難しくなっているため、AIの信頼性を向上させるにはHalluHardのような困難な検証環境が不可欠であると結論付けている。
この記事のタイトルとURLをコピーします